フィルタによる処理
標準入力からデータを受け取り、受け取ったデータを加工して標準出力に出力する機能。
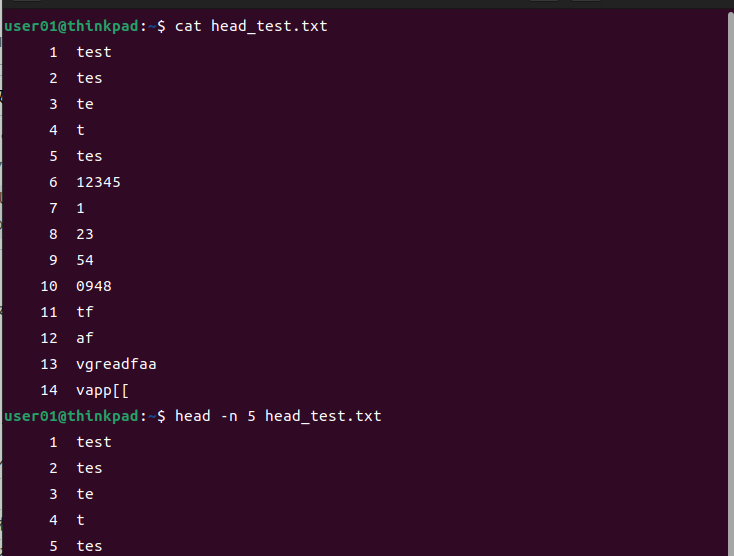
headコマンド
head [オプション] [ファイル名...]
| オプション | 説明 |
|---|---|
| -n 行数 | 指定された行数分だけ表示する |
| -c バイト数 | 出力するバイト数を指定する |
テキストファイルの先頭部分を表示する。
オプションnで行数を指定しない場合、デフォルトで10行まで表示する。
tailコマンド
tail [オプション] [ファイル名...]
| オプション | 説明 |
|---|---|
| -n 行数 | 指定された行数分だけ表示する |
| -f |
ファイルの末尾が常に追記されているものと仮定して、 最終部分を読み続ける。 |
テキストファイルの末尾部分を表示する。
headコマンド同様、オプションnなしで実行するとデフォルトで10行まで表示する。

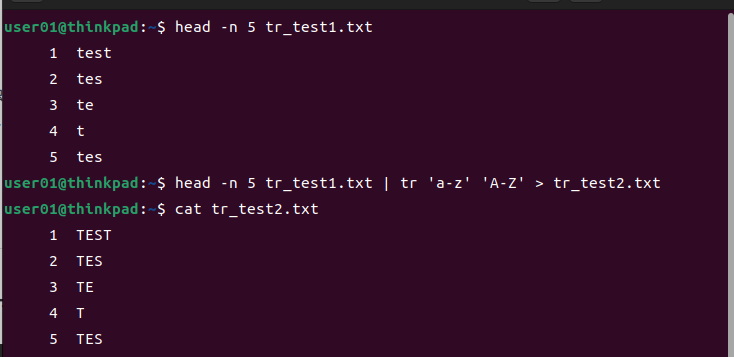
trコマンド
tr [オプション] [文字郡1] [文字郡2]
| オプション | 説明 |
|---|---|
| -d 文字郡1 | 文字郡1で一致した文字を削除する |
| -s 文字郡1 文字郡2 |
文字郡1で一致した文字を文字郡2に置換する |
標準入力の文字を指定のフォーマットに変換して、標準出力する。
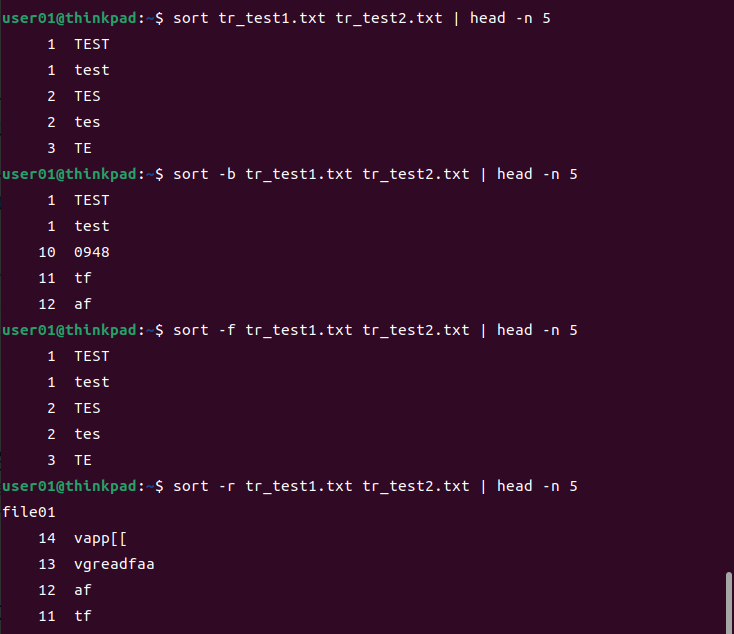
sortコマンド
sort [オプション] [ファイル名...]
| オプション | 説明 |
|---|---|
| -b | 先頭の空白を無視する |
| -f |
大文字・小文字を区別しない |
| -r |
降順にソートする |
ファイル内容をソートして標準出力する。
デフォルトでは昇順、オプションrを指定すると降順。
ファイルが複数ある場合は、各ファイルの内容を並び替えた後に連結して出力。
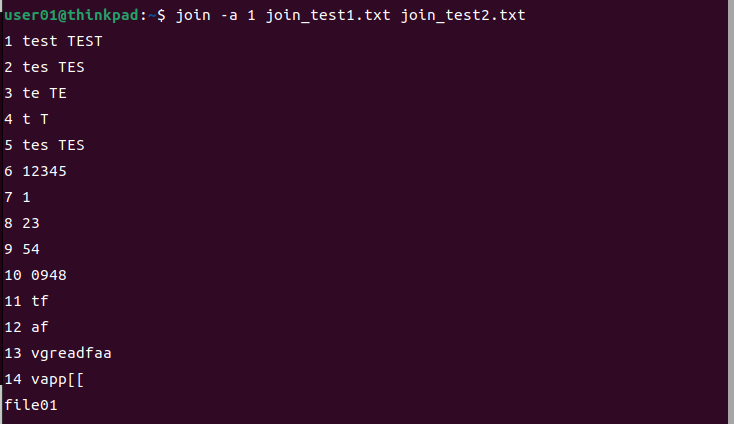
joinコマンド
join [オプション] [ファイル名(番号1)] [ファイル名(番号2)]
| オプション | 説明 |
|---|---|
| -a ファイル番号 | 指定したファイルの番号の内容を全て表示する。空白の場合も行を表示する |
| -j フィールド | 連結するフィールドを指定する |
引数で指定された2つのファイルを読み込んで、共通のフィールドを持つ行を連結する。通常、フィールドは空白、タブ、改行文字で区切られる。

uniqコマンド
uniq [オプション] [入力ファイル[出力ファイル]]
| オプション | 説明 |
|---|---|
| -c | 行の前に出現回数を出力する |
| -d | 重複した行のみ出力する |
| -u | 重複していない行のみ出力する |
標準入力から行を読み取り、重複する行を取り除いて標準出力する。
標準入力は予めソートしておかなければ、思いもしない結果になってしまう。
